

The Token Bottleneck: Why Agentic Workflows Are Forcing a Structural Revolution in Martech
The marketing technology (martech) sector is facing a quiet but profound architectural crisis. In the early days of the generative artificial intelligence boom, marketing teams eagerly adopted platforms like ChatGPT and Claude, treating them as low-cost, "all-you-can-eat" intellectual buffets. For a flat monthly subscription of roughly $20 per user, marketers could generate endless copy, brainstorm campaign ideas, and summarize long documents.
However, this pricing model is rapidly disappearing. AI providers are shifting toward usage-based, token-centric pricing models. This structural shift is occurring at the exact moment the industry is transitioning from simple, single-prompt interactions to complex, autonomous "agentic workflows."
Because AI agents require vast amounts of data to execute multi-step marketing pipelines, they consume tokens at an exponential rate. If marketing organizations are to keep operational costs under control while meeting the growing demand for automation, the underlying infrastructure of martech must undergo a fundamental redesign.
Main Facts: The Token Bottleneck in Modern Martech
At the core of this transition is a technical clash between how AI models process information and how marketing departments run their daily operations.
[Business Systems (CRM/Data Warehouse)]
│
▼ (MCP / APIs)
[Agentic Workflow] <─── [Internal Reasoning Loop]
│ (Re-evaluates task history at every step)
▼
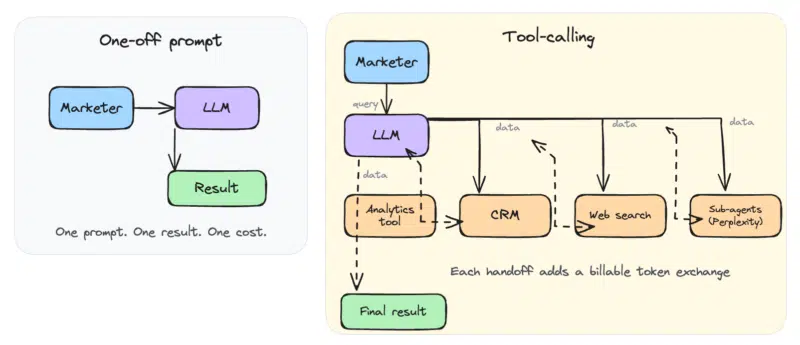
[Token Consumption] ───► High Operational Costs & ThrottlingWhen an AI system is connected directly to corporate data, its utility increases dramatically. Rather than acting as an isolated chatbot that answers one prompt at a time, a connected agent can pull customer records from a CRM (such as Salesforce or HubSpot), analyze ongoing campaign performance, search the web for competitor pricing, and generate a highly personalized marketing report in a single, unified workflow.
This level of automation is made possible by two primary technical mechanisms:
- Tool Calling APIs: These allow the language model to write and execute code or make calls to external software databases.
- Model Context Protocol (MCP): An open standard that establishes secure, bidirectional connections between AI models and local or cloud-based data sources.
While these tools provide an unprecedented boost to marketing productivity by eliminating the need for human operators to jump between multiple applications, they come with a major financial catch: every single tool call consumes tokens.
An AI agent does not simply read a prompt and write an answer. To solve complex, multi-step problems, an agent operates in a continuous loop. At each step of this loop, the agent must pass its entire task history, its internal reasoning chain, and any data retrieved from external tools back through the model. This iterative process causes token consumption to skyrocket, creating a cost structure that is highly unsustainable under traditional SaaS budgeting.
Chronology: From Simple Chatbots to Autonomous Agents
To understand how the martech ecosystem arrived at this financial inflection point, it is helpful to trace the rapid evolution of enterprise AI integration over the last several years.
2022–2023 2024 2025–2026
┌───────────────────────────┐ ┌───────────────────────────┐ ┌───────────────────────────┐
│ Flat-Rate Era │ │ Integration Era │ │ Agentic Era │
│ • Simple Q&A │ │ • Tool Calling & APIs │ │ • Multi-step loops │
│ • Low, predictable costs │ │ • CRM & search connection │ │ • Token usage explodes │
│ • Isolated chatbots │ │ • Workflows begin to sync │ │ • Infrastructure crisis │
└───────────────────────────┘ └───────────────────────────┘ └───────────────────────────┘Phase 1: The Flat-Rate Era (2022–2023)
The initial wave of generative AI adoption was characterized by isolated, prompt-and-response interactions. Marketers used web interfaces to write copy, brainstorm ideas, and draft emails. Because these tasks were self-contained and executed manually by human users, token usage was minimal. AI providers subsidized compute costs to capture market share, offering generous free tiers and low-cost flat-rate monthly subscriptions.
Phase 2: The Integration Era (2024)
As organizations sought to embed AI deeper into their operations, developers began connecting models to external systems. The widespread adoption of tool calling and APIs allowed AI to pull live data from web searches and internal databases. While this made the technology far more capable, it marked the end of predictable pricing, as background processes began running multiple API calls behind the scenes for a single user query.

Phase 3: The Agentic Era (2025–2026)
Today, the industry has entered the era of autonomous agents. Instead of waiting for human instruction at every turn, agents are deployed to run continuous, multi-step marketing pipelines—such as real-time social listening, automated lead scoring, and dynamic ad generation. Because these agents run in autonomous loops, re-evaluating their progress at every step, they consume more tokens in a single afternoon than a human copywriter would use in an entire month.
Consequently, teams relying on standard subscription tiers are hitting strict usage limits within the first two weeks of their billing cycles, forcing them to choose between workflow disruption or expensive overage fees.
Supporting Data: The Compounding Cost of Agentic Loops
The financial impact of this architectural shift is clear when looking at standard industry tokenization metrics. A token is the basic unit of data processed by a large language model (LLM), roughly equivalent to four characters or 0.75 words in English.
Consider a typical, moderate daily marketing pipeline designed to monitor brand sentiment:
- Search & Retrieval: The agent searches the web or social media platforms, retrieving 200 raw text results.
- Summarization: The agent processes and condenses these results to identify key trends.
- Content Generation: The agent drafts five distinct headline variations based on the summarized trends.
┌────────────────────────────────────────────────────────────────────────┐
│ DAILY SENTIMENT PIPELINE │
├──────────────────────────────┬─────────────────────────────────────────┤
│ Step 1: Search & Retrieval │ Retrieves 200 raw social/web results │
├──────────────────────────────┼─────────────────────────────────────────┤
│ Step 2: Summarization │ Processes and condenses text │
├──────────────────────────────┼─────────────────────────────────────────┤
│ Step 3: Content Generation │ Drafts 5 headline variations │
├──────────────────────────────┴─────────────────────────────────────────┤
│ Average Token Cost Per Run: 4,000 – 5,000+ tokens │
│ Monthly Total (30 Days): 120,000 – 150,000+ tokens │
└────────────────────────────────────────────────────────────────────────┘A single run of this relatively simple pipeline can easily consume 4,000 to 5,000 tokens. When executed daily over a 30-day month, a single pipeline will run up well over 120,000 to 150,000 tokens.
This usage quickly blows past the free-tier limits of major model providers like OpenAI and Anthropic. For teams running multiple pipelines across various brands, products, and channels, these costs compound exponentially.
This economic reality is further complicated by a fundamental truth of language models. As marketing technology experts Scott Brinker and Frans Riemersma point out in the State of Martech 2026 report:
"More input does not automatically mean better output."
In traditional software, processing more data generally yields a more comprehensive result. In generative AI, however, feeding raw, unfiltered datasets into a prompt window often introduces noise, dilutes the model’s focus, and increases the likelihood of hallucinations—all while driving up the token count. Under current usage-based pricing models, enterprises are paying premium rates for raw data processing that may actually degrade the quality of their marketing insights.
Official Responses: The Architectural Shift to "Owned Context"
Faced with rising costs and performance bottlenecks, forward-thinking enterprise teams and software developers are moving away from a "provider-centric" model. Instead of routing all raw data directly to commercial AI models, organizations are adopting an architecture built on owned context.
[ Raw Data Sources ]
│
▼
[ Local Team Database / Warehouse ]
(PostgreSQL, Qdrant, Snowflake, etc.)
│
▼
[ Lightweight Non-LLM Filtering ]
(Vector Search / Keyword Scoring)
│ (Reduces data by 60%+)
▼
[ Only Relevant Data ]
│
▼
[ Commercial LLM API ]The core principle of owned context is simple: keep your raw data under your own control, and only send highly refined, highly relevant information to the LLM.
Instead of relying on a commercial model provider to act as both your database and your reasoning engine, organizations are structured as follows:
- Local Storage: Raw data is ingested and stored in secure, team-controlled environments. These can include relational databases like PostgreSQL, vector databases optimized for AI like Qdrant, or cloud data warehouses such as Snowflake and Google BigQuery.
- Non-LLM Pre-Filtering: Once the data is centralized, developers apply lightweight, non-LLM filtering logic to sort and rank the information before it ever touches a commercial model API. This step uses traditional, computationally inexpensive methods like keyword scoring or vector similarity search. These algorithms can process millions of data points for a fraction of a cent.
- Targeted Inference: When a marketing pipeline runs, the pre-filtering step identifies the most relevant data points and passes only those to the model.
For example, if a social listening agent pulls 500 tweets about a brand, the local vector database can quickly isolate the 10 most critical messages. Only these 10 tweets are sent to the LLM for sentiment analysis and strategic recommendations. By shifting the heavy lifting of data retrieval away from the LLM, organizations routinely see token cost reductions of 60% or more, with zero loss in the quality of the generated insights.
Tooling in the Agent Ecosystem
This architectural shift has fueled the rise of open-source and provider-agnostic tools designed to help enterprises maintain control over their context:
- Hermes Agent: An open-source framework developed by Nous Research. Unlike proprietary tools tied to specific vendor ecosystems, Hermes runs directly on an organization’s own infrastructure. It maintains a persistent local context store—including conversation histories, tool outputs, and vector embeddings—in a private database. It also features a local memory layer that learns user preferences and recurring patterns over time, ensuring the agent improves without needing to rebuild its context from scratch in every session.
- Claude Cowork / Claude Code: Native environments designed by Anthropic to streamline developer and marketer workflows. While highly capable at tool calling and file management, they are tightly coupled with Anthropic’s proprietary models and infrastructure, keeping users within their ecosystem.
- Perplexity Computer: An agentic search and execution tool designed to automate web-research workflows, though it remains tied to Perplexity’s infrastructure and model APIs.
The defining characteristic of tools like Hermes Agent is that the language model acts as a guest in your system, not the landlord. Because the framework is provider-agnostic, a developer can swap out the underlying model with a single line of code—switching from a commercial API like OpenRouter to a self-hosted, open-weights model like Meta’s LLaMA as cost and performance needs change.
Strategic Implications: Redefining the Martech Infrastructure
The shift toward agentic workflows and owned context marks a major turning point for the martech industry, forcing CMOs and technology leaders to make a fundamental strategic choice:
Do you want to pay for the work, or do you want to own the infrastructure and pay only for the reasoning?
Continuing with a provider-centric, subscription-heavy approach is increasingly untenable for large-scale operations. Simply upgrading to higher subscription tiers does not solve the underlying issue; it merely delays the point at which an enterprise hits its capacity limits.
By contrast, adopting an "owned context" architecture offers several key advantages:
- Long-Term Cost Stability: By offloading data retrieval and preliminary filtering to local databases, enterprises can scale their marketing automation pipelines without experiencing a linear increase in their API bills.
- Data Security and Sovereignty: Keeping customer data within self-hosted databases (like PostgreSQL or corporate cloud warehouses) ensures sensitive CRM records are not continuously passed to external model providers for processing.
- Vendor Flexibility: Organizations that own their context layer can easily swap model providers as the AI market evolves. If a competitor releases a faster, cheaper, or more accurate model, the enterprise can transition immediately without needing to rebuild its entire data pipeline.
As marketing departments continue to integrate autonomous agents into their daily operations, the winners of the next wave of digital transformation will not be those who write the most clever prompts. The winners will be the organizations that build the infrastructure to own their context, protect their data, and run highly optimized, cost-effective AI operations at scale.
