
The Science of Precision: A Comprehensive Guide to Email A/B Testing
In the hyper-competitive landscape of digital marketing, intuition is a dangerous substitute for data. As consumer inboxes become increasingly crowded, the margin for error in email communication has shrunk to near zero. Enter email A/B testing—a rigorous, data-driven methodology that transforms guesswork into a repeatable science. By systematically comparing two versions of an email, marketers can move beyond vanity metrics and identify the specific triggers that drive audience engagement, conversion, and long-term brand loyalty.
The Fundamentals of Email A/B Testing
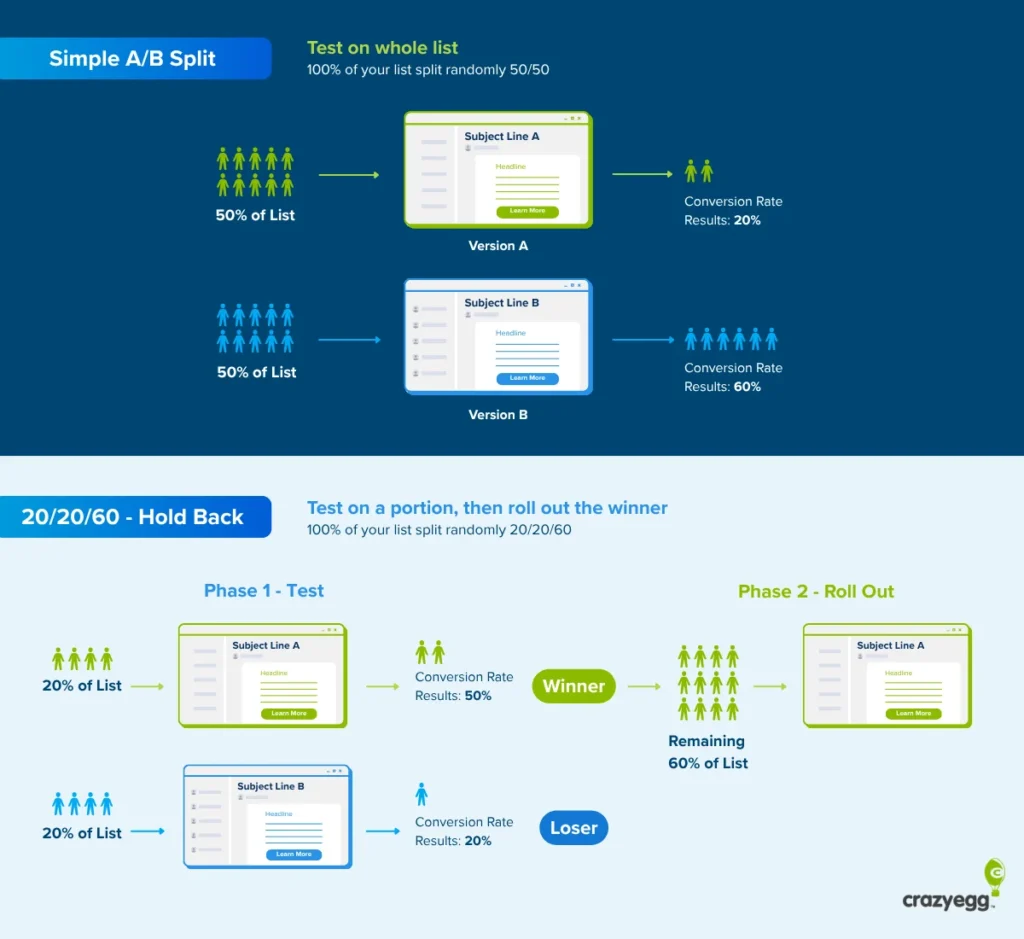
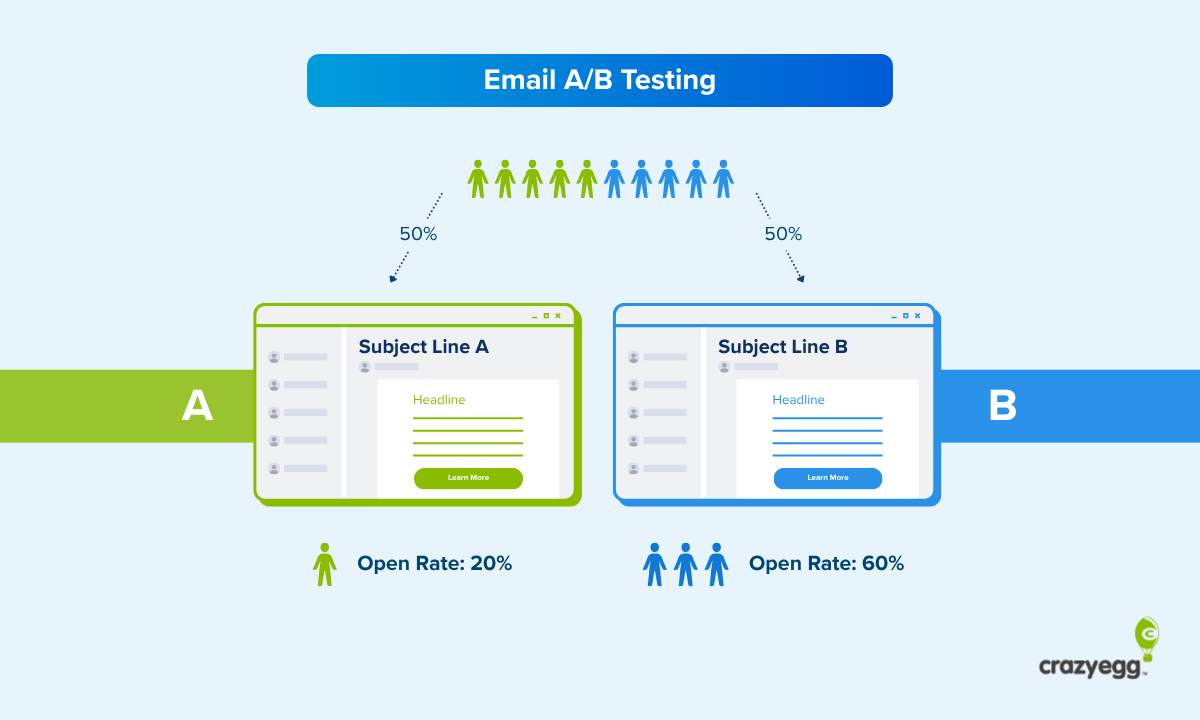
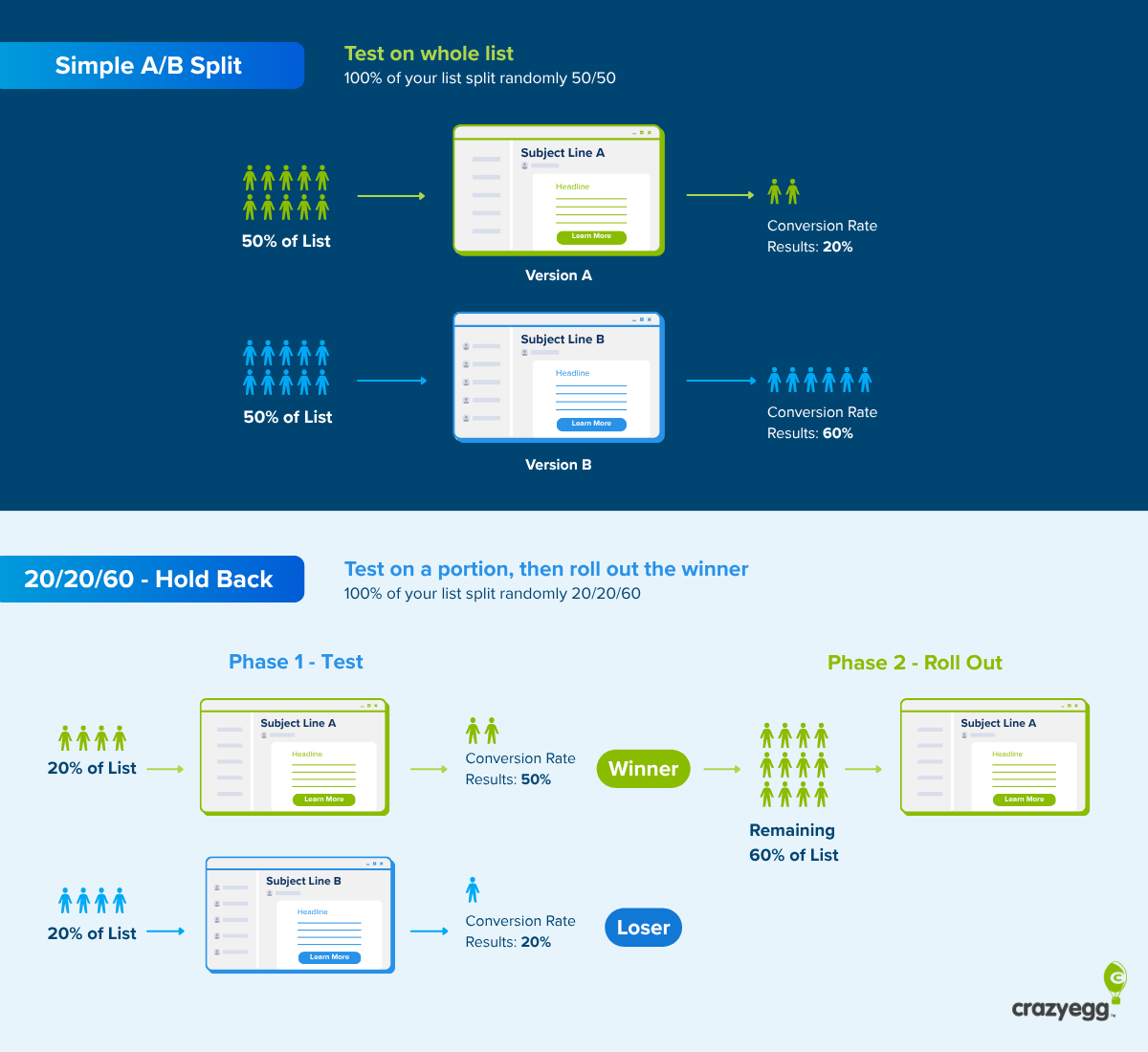
At its core, email A/B testing—frequently referred to as split testing or bucket testing—is a controlled experiment. The premise is straightforward: you divide your recipient list into randomized, representative subgroups. Group A receives the "control" version (the baseline), while Group B receives the "variant" (the treatment), which features a single, deliberate modification.
Because email interaction is binary—a recipient either opens the message or ignores it; they click a call-to-action (CTA) or they don’t—the data gathered is exceptionally clean and quantifiable. This clarity allows marketing teams to isolate variables and attribute performance fluctuations directly to the changes made, providing an empirical roadmap for future campaign optimization.
The Strategic Benefits of Split Testing
The adoption of a formal testing culture provides three primary advantages for organizations:
- Objective Decision-Making: By removing the "HIPPO" (Highest Paid Person’s Opinion) from the creative process, testing ensures that strategy is dictated by the audience’s actual behavior rather than internal assumptions.
- Revenue Maximization: Small, iterative improvements to click-through rates (CTR) often compound over time, leading to significant increases in lead generation and direct sales without requiring a larger list or increased advertising spend.
- Enhanced Audience Insights: Continuous testing acts as a feedback loop. Over time, you begin to build a library of "audience preferences"—data points that inform not just your email strategy, but your broader content marketing and product positioning efforts.
Chronology: A Nine-Step Framework for Execution
To ensure the integrity of your results, the testing process must be disciplined and standardized. Follow this nine-step lifecycle to maintain rigor:
- Define the Hypothesis: Never test without a question. State it clearly: "I believe that using a personalized subject line will increase open rates by 5% compared to a generic subject line."
- Isolate the Variable: Select one element to change. Testing multiple variables at once (multivariate testing) requires massive data sets to be accurate; keep it simple initially.
- Determine the Sample Size: Use a statistical significance calculator to ensure your audience is large enough to produce reliable data.
- Randomize the Split: Ensure the audience segments are statistically identical to prevent bias (e.g., don’t send one version to mobile users and another to desktop users).
- Select the Primary Metric: Choose your success indicator before the send. Is it the open rate, the click-through rate, or the final conversion?
- Execute the Send: Distribute the emails simultaneously to avoid time-of-day bias.
- Monitor Performance: Allow sufficient time for the data to accumulate.
- Analyze the Outcome: Compare the results against your initial hypothesis.
- Apply and Repeat: Implement the winner across the remaining audience and document the findings to inform the next experiment.
High-Impact Levers vs. Cosmetic Tweaks
Not all variables are created equal. When resources are finite, prioritize elements that exert the most influence on user psychology.
Prioritize These High-Impact Levers:
- Subject Lines: The most critical barrier to entry. If they don’t open it, they can’t see the content.
- The Offer: Is the value proposition clear? Changing the incentive (e.g., "20% off" vs. "Free Shipping") often yields the most dramatic shifts in conversion.
- Call-to-Action (CTA): The primary bridge to your landing page. Test button copy ("Get Started" vs. "Claim My Trial") and placement.
- Content Angle: Test the narrative approach—is your audience more responsive to a pain-point-driven message or a benefit-driven message?
De-prioritize These Low-Impact Tweaks:
Unless you are a high-volume sender (sending millions of emails monthly), avoid wasting statistical significance on:
- Minor Color Changes: Changing a button from blue to slightly lighter blue rarely moves the needle.
- Font Choices: Unless legibility is compromised, the impact is negligible.
- Image Swaps: While imagery matters, it is secondary to the copy and the offer.
Metrics That Matter: Beyond the Open Rate
While "Open Rate" is the standard industry metric, it is often a "vanity metric" in the post-iOS privacy era. A more robust testing framework monitors:
- Click-to-Open Rate (CTOR): This measures how many people who actually opened the email found the content compelling enough to click.
- Conversion Rate: The ultimate goal. How many recipients completed the desired action?
- Unsubscribe and Spam Rates: The "negative" metrics. If a version leads to a spike in unsubscribes, it is a failed test, even if the open rate is high.
Ensuring Trust: Statistical Significance and Validation
A common mistake is declaring a winner too early. If your test reports a "win" after only 100 sends, the results are likely coincidental.
The Gold Standard: Aim for 95% statistical significance (a p-value of less than 0.05). This provides the mathematical confidence that the variance in performance is due to your changes, not random noise.
The A/A Test Protocol: To verify your platform’s integrity, occasionally run an "A/A test"—sending the exact same email to two segments. If your system reports a significant difference between two identical emails, your testing protocol is fundamentally broken, and your data cannot be trusted.
The Role of AI in Modern Testing
Generative AI and predictive analytics have fundamentally altered the efficiency of A/B testing.
- Generative Content: AI tools can now draft dozens of subject line variations based on historical best-performers, allowing marketers to test nuances in tone and urgency at scale.
- Predictive Personalization: Modern ESPs (Email Service Providers) use AI to score individual contacts. Instead of a manual 50/50 split, these platforms can dynamically serve the most likely-to-succeed version of an email to specific audience subsets, optimizing results in real-time.
Implications and Common Pitfalls
The primary danger in A/B testing is "Testing for the sake of testing." Without a clear hypothesis, you are simply gathering noise.
Common Mistakes to Avoid:
- Testing Too Many Variables: If you change the subject line and the CTA simultaneously, you will never know which change drove the performance boost.
- Short-Circuiting the Timeline: If you stop a test before the audience has time to engage (e.g., stopping a purchase-based test after only two hours), you are missing the tail end of the data.
- Ignoring the "Small List" Problem: If your list is under 1,000 subscribers, formal A/B testing is often statistically impossible. In these cases, focus on qualitative research and "sequential testing"—where you compare campaign performance over different time periods rather than a simultaneous split.
Conclusion: The Path Forward
Email A/B testing is not merely a technical exercise; it is an organizational mindset. It requires the humility to admit that our creative assumptions may be wrong and the discipline to let the data lead the way. By focusing on high-impact levers, ensuring statistical validity, and leveraging AI for creative assistance, marketers can build a high-performance email program that respects the subscriber’s time while delivering consistent, measurable results.
As technology evolves, the tools will get faster, but the principle remains timeless: listen to your audience, test your assumptions, and let the data dictate the evolution of your brand’s voice.
