
John Mueller, do Google, foi questionado em um podcast sobre SEO se impedir que uma página seja rastreada afetaria o valor dos links internos ou externos que ela contém. Sua resposta forneceu uma abordagem inovadora para essa questão e revelou insights sobre como o Google Search lida com esse tipo de situação internamente.
A respeito da influência das conexões.
Existem diversas formas de abordar os links, no entanto, em relação aos links internos, o que o Google destaca repetidamente é a utilização desses links para indicar ao Google quais páginas possuem maior relevância.
Google não lançou recentemente patentes ou artigos de pesquisa sobre sua utilização de links externos para classificar páginas da web. Portanto, a maioria do conhecimento dos profissionais de SEO sobre esse assunto é baseado em informações antigas, que podem estar desatualizadas.
O comentário de John Mueller não contribui para o nosso entendimento sobre como o Google utiliza os links de entrada ou internos, porém apresenta uma abordagem diferente que considero mais proveitosa do que inicialmente parece.
Impacto nas ligações quando a indexação é bloqueada.
A pessoa que fez a pergunta estava interessada em saber se impedir o Google de rastrear uma página da web teve algum impacto na forma como o Google utiliza os links internos e inbound.
Essa é a problemática em questão.
O impedimento de rastreamento ou indexação em uma URL resulta na perda da capacidade de estabelecer conexões por meio de links tanto externos quanto internos?
Mueller propõe que se busque uma resposta para a pergunta considerando a reação de um usuário, o que é uma abordagem intrigante e reveladora.
Ele deu uma resposta:
Eu avaliaria a situação sob a perspectiva de um usuário comum. Se uma página não estiver acessível para eles, então não poderão interagir de forma eficaz, tornando os links contidos nessa página menos significativos.
O que foi mencionado está de acordo com nosso conhecimento sobre a ligação entre rastreamento, indexação e links. Se o Google não puder rastrear um link, ele não será visível para o Google e, consequentemente, não terá impacto.
Comparação entre Palavra-chave e Abordagem centrada no usuário em conexões.
A ideia de Mueller de examinar a situação sob a perspectiva de um usuário é intrigante, já que foge do modo habitual de pensar sobre a questão dos links. No entanto, faz sentido, pois se alguém for impedido de acessar uma página da web, naturalmente não conseguirá visualizar os links presentes nela, concorda?
E quanto aos links de fora? Em um passado distante, testemunhei um link pago para um site de tinta de impressora em uma página sobre tinta de polvo em um site de biologia marinha. Naquela época, os criadores de links acreditavam que se uma página da web contivesse palavras que correspondessem ao conteúdo da página de destino (por exemplo, “tinta de polvo” para a “tinta” da impressora), o Google usaria esse link para classificar a página, pois estava em um site “relevante”.
Como soa diferente hoje em dia, muitos indivíduos costumavam confiar na estratégia “baseada em palavras-chave” para interpretar links, em contraste com a abordagem focada no usuário recomendada por John Mueller. Sob uma perspectiva centrada no usuário, a compreensão de links se torna mais simples e tende a estar mais alinhada com a maneira como o Google classifica os links do que a abordagem ultrapassada baseada em palavras-chave.
Melhorar os links para que possam ser rastreados.
Mueller reiterou a importância de garantir que as páginas sejam facilmente encontradas por meio de links.
Ele deu uma explicação.
Se deseja aumentar a visibilidade de uma página, certifique-se de que ela seja vinculada a partir de páginas relevantes e indexáveis em seu site. Bloquear a indexação de páginas que não deseja que sejam descobertas é uma opção, porém, se uma parte essencial do seu site está vinculada a partir de uma página bloqueada, isso pode dificultar a pesquisa.
Informações sobre Bloqueio de Rastreamento
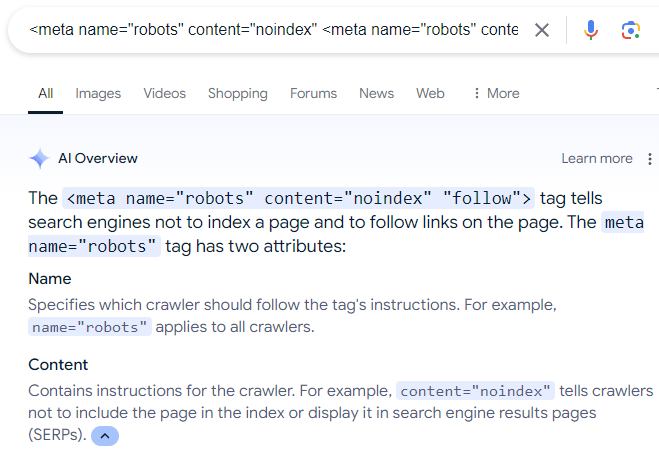
Última observação sobre a prática de impedir que os motores de busca indexem páginas da web que foram rastreadas. Um equívoco frequente entre alguns donos de sites é o uso da meta tag “robots” para instruir o Google a não indexar uma página da web, mas permitindo o rastreamento dos links presentes na página.
A instrução (equivocada) parece desta maneira:
O texto contém uma tag meta com o atributo content com o valor “noindex” e o atributo name com o valor “robots”, e também possui o atributo “follow”.
Existem muitas informações incorretas na internet que sugerem a importância da meta descrição, inclusive refletidas nos resumos de IA do Google.
Resumo da AI por meio de captura de tela.
chsyys/PixaBay
É evidente que a instrução de robôs mencionada não é eficaz, pois, de acordo com Mueller, se uma página da web não é visível para uma pessoa ou motor de busca, então essa pessoa ou motor de busca não conseguirá acessar os links contidos na página.
Adicionalmente, embora exista uma regra de diretiva “nofollow” que pode ser empregada para que um mecanismo de busca ignore os links em uma página da web, não existe uma diretiva “follow” que obrigue um mecanismo de busca a seguir todos os links em uma página da web. A decisão de seguir os links é uma escolha que o mecanismo de busca pode fazer por conta própria.
Explore mais informações a respeito das meta tags para robôs.
Escute a resposta de John Mueller à pergunta da marca de 14:45 minutos do podcast.
A imagem principal é fornecida por Shutterstock/ShotPrime Studio.



